什么是贝叶斯模型(贝叶斯在实际应用简单举例)
2022-12-21
说到贝叶斯模型,就算不是搞数据分析的人应该都会有所耳闻,因为它的应用范围实在是太广了,大数据、机器学习、数据挖掘、数据分析等领域几乎都能够找到贝叶斯模型的影子,甚至在金融投资、日常生活中我们都会用到,但是却很少有人真正理解这个模型。
什么是贝叶斯模型
在介绍贝叶斯模型之前,我们先看一个经典的贝叶斯数据挖掘案例:
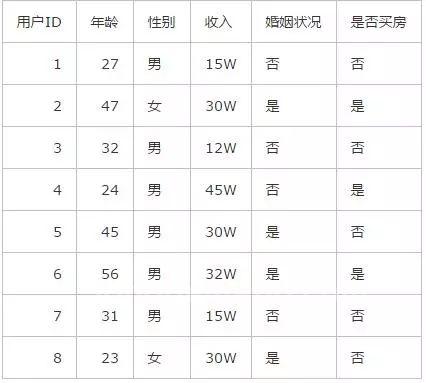
如果你在一家购房机构上班,今天有8个客户来跟你进行了购房沟通,最终你将这8个客户的信息录入了系统之中:
此时又有一个客户走了进来,经过交流你得到了这个客户的信息:
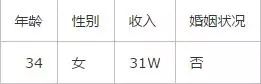
那么你是否能够判断出这位客户会不会买你的房子呢?
如果你没有接触过贝叶斯理论,你就会想,原来的8个客户只有3个买房了,5个没有买房,那么新来的这个客户买房的意愿应该也只有3/8 。
这代表了传统的频率主义理论,就跟抛硬币一样,抛了100次,50次都是正面,那么就可以得出硬币正面朝上的概率永远是50%,这个数值是固定不会改变的。例子里的8个客户就相当于8次重复试验,其结果基本上代表了之后所有重复试验的结果,也就是之后所有客户买房的几率基本都是3/8 。
但此时你又觉得似乎有些不对,不同的客户有着不同的条件,其买房概率是不相同的,怎么能用一个趋向结果代表所有的客户呢?
对了!这就是贝叶斯理论的思想,简单点讲就是要在已知条件的前提下,先设定一个假设,然后通过先验实验来更新这个概率,每个不同的实验都会带来不同的概率,这就是贝叶斯公式:
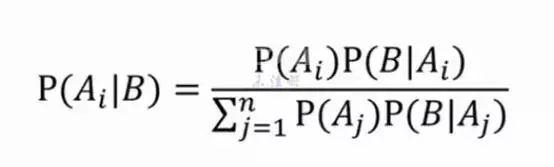
按照这个公式,我们就可以完美解决上面的这个例子:
先找出“年龄”、“性别”、“收入”、“婚姻状况”这四个维度中买房和不买房的概率:
年龄
P(b1|a1) :30-40买房的概率是1/3
P(b1|a2) :30-40没买房的概率是2/5
收入
P(b2|a1) --- 20-40买房的概率是2/3
P(b2|a2) --- 20-40没买房的概率是2/5
婚姻状况
P(b3|a1) --- 未婚买房的概率是1/3
P(b3|a2) --- 未婚没买房的概率是3/5
性别:
P(b4|a1) --- 女性买房的概率是1/3
P(b4|a2) --- 女性没买房的概率是1/5
OK,现在将所有的数据代入到贝叶斯公式中整合:
新用户买房的统计概率为P(b|a1)P(a1)=0.33*0.66*0.33*0.33*3/8=0.0089
新用户不会买房的统计概率为P(b|a2)P(a2)=0.4*0.4*0.6*0.2*5/8=0.012
所以可以得出结论:新用户不买房的概率更大一些。
怎么做贝叶斯模型
贝叶斯的工作流程可以分为三个阶段进行,分别是准备阶段、分类器训练阶段和应用阶段。
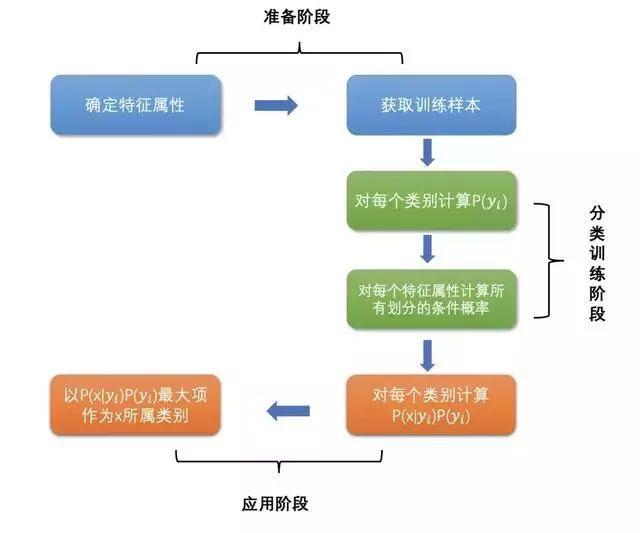
1、准备阶段:
这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,去除高度相关性的属性,然后由人工对一部分待分类项进行分类,形成训练样本集合。
这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。(相当于上述例子中那8个客户的信息,这个步骤是需要人工进行整合的)
2、分类器训练阶段:
这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。
这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
3、应用阶段:
这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。
这一阶段也是机械性阶段,由程序完成。
贝叶斯有什么优缺点?
贝叶斯模型的优点有4个,分别是:
贝叶斯模型发源于古典数学理论,有稳定的分类效率。
对缺失数据不太敏感,算法也比较简单,常用于文本分类。
分类准确度高,速度快。
对小规模的数据表现很好,能处理多分类任务,适合增量式训练,当数据量超出内存时,我们可以一批批的去增量训练
贝叶斯模型的缺点有3个,分别是:
对训练数据的依赖性很强,如果训练数据误差较大,那么预测出来的效果就会不佳。
在实际中,属性个数比较多或者属性之间相关性较大时,分类效果不好。
需要知道先验概率,且先验概率很多时候是基于假设或者已有的训练数据所得的,这在某些时候可能会因为假设先验概率的原因出现分类决策上的错误。
运营数据分析中的贝叶斯陷阱
通过以上案例大家对贝叶斯定律肯定都有了一定的了解,贝叶斯在运营工作中有什么应用呢?说实话,本来我对贝叶斯在运营工作中能有多大的作用,并没有概念,直到我在日常一活动复盘中发下了下面的案例。
我们经常会举办一些训练营活动,活动分为招募期、课程期两个时段。在招募过程我们会投放很多渠道,在结束后我们都会做复盘报告。
在复盘的过程中我们发现了一个有趣的数据,参与我们训练营的用户画像调研中,工作经验为1-3年的开发者居多,占比在70%以上。因此,我们每一期活动复盘报告中,都会如下分析:
参与活动的开发者以1-3年工作经验者居多,说明我们的课程内容对此类开发者更具有吸引力,可以针对此类开发者,做课程设计上的优化。
那么大家有没有发现关于这个数据的复盘分析有没有什么问题?
我们的训练营报名用户的工作年限是1-3年居多,这是一个结果,我们只针对这个结果进行了分析。那么按照贝叶斯定律,很明显我们忽略了导致这个结果的前提条件。这个前提条件的忽略最终可能影响了我们对整件事情的判断。这个前提条件就是:我们的投放渠道。
我们投放渠道所覆盖的用户的工作年限是多少?如果该活动投放的渠道所覆盖的用户就是1-3年工作经验开发者居多,自然报名训练营的用户也会是这个群体,那我们的复盘就是错误的,并不能说明我们的课程对工作1-3年的开发者更具有吸引力。
如果我们的投放渠道用户分布平均,而活动报名用户出现了如上的分布,那我们的复盘总结便是有意义的。
在意识到以上因素后,我们在后续活动的数据模型中,增加了投放渠道用户画像的收集,用以完善数据完整度,避免出现原先错误的分析结论。
所以,以上便是贝叶斯定律在日常运营活动中的应用,掌握贝叶斯理论,在运营活动中可以避免我们做出错误的数据分析,以免被错误数据误导而对运营策略产生影响。